
ARC AGI 3 Benchmark: Warum Systeme besser sind
Wer sich heute mit Künstlicher Intelligenz beschäftigt, landet fast automatisch bei einer einzigen Frage: Welches Modell ist besser? Genau hier setzt der ARC AGI 3 Benchmark an. Größer, schneller, genauer. Der Wettbewerb dreht sich fast nur um diese Ebene. Hier liegt das eigentliche Problem. Denn reale Aufgaben bestehen selten aus einer einzelnen Antwort. Sie bestehen aus mehreren Schritten, Entscheidungen und Abhängigkeiten, die sauber zusammengeführt werden müssen.
Ein Modell kann Texte generieren, Fragen beantworten oder Code schreiben, und das funktioniert gut, solange die Aufgabe klar abgegrenzt ist. Sobald jedoch mehrere Schritte notwendig werden, zeigt sich eine Grenze, weil die Struktur fehlt. An diesem Punkt greift der ARC AGI 3 Benchmark erneut ein. Er ist kein weiterer Vergleich von Modellen. Er ist ein Realitätstest für echte Problemlösung. Das Ergebnis fällt deutlich aus. Klassische KI-Modelle schneiden extrem schlecht ab. Agentische Systeme liefern spürbar bessere Resultate.
Hier entsteht eine entscheidende Frage. Wenn Modelle allein nicht ausreichen, wo entsteht dann die eigentliche Leistung? Liegt der Fortschritt wirklich im Modell selbst? Oder liegt er in der Art, wie diese Modelle eingesetzt und gesteuert werden?
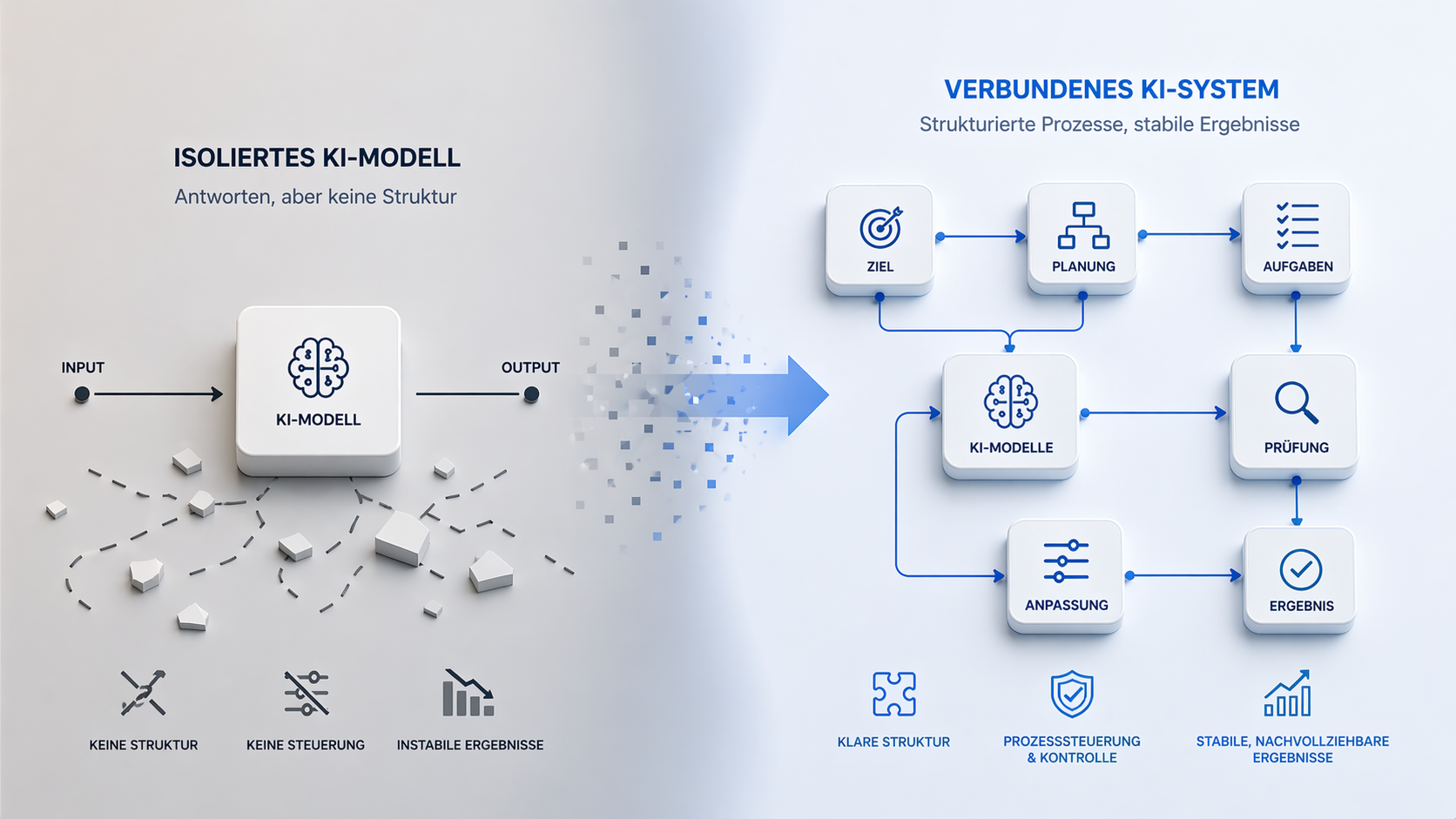
Genau an diesem Punkt verschiebt sich die Perspektive. Nicht das Modell allein bestimmt die Qualität der Ergebnisse. Entscheidend ist die Struktur, in der es arbeitet. Genau dieser Unterschied, zwischen isolierter KI und einem funktionierenden System, steht im Zentrum dieses Artikels.
ARC AGI 3 Benchmark: Was er wirklich misst
ARC AGI 3 Benchmark: Mehr als nur ein weiterer KI-Test
Der ARC AGI 3 Benchmark wirkt auf den ersten Blick wie ein weiterer Leistungsvergleich. Genau das ist er aber nicht. Übliche Tests prüfen vor allem, wie gut ein Modell Wissen wiedergibt oder bekannte Muster erkennt. Genau hier setzt ARC AGI 3 anders an. Im Mittelpunkt steht eine andere Frage. Kann ein System ein Problem eigenständig strukturieren und lösen?
Hier liegt der entscheidende Unterschied. Klassische Benchmarks funktionieren oft wie Wissenstests. Sie prüfen, ob ein Modell die richtige Antwort kennt. ARC AGI 3 geht einen Schritt weiter. Der Test zielt auf echte Problemlösung. Damit rückt er näher an die Realität heran. Denn im Alltag geht es selten um einzelne Antworten. Es geht um Abläufe. Mehrere Schritte müssen zusammengeführt werden. Entscheidungen greifen ineinander. Zusammenhänge müssen erkannt werden. Genau das bildet der Benchmark ab.
Die Relevanz entsteht nicht durch technische Komplexität. Sie entsteht durch die Aussagekraft. Der Test zeigt, ob ein System über reine Ausgabe hinausgehen kann, und damit echte Problemlösung ermöglicht. Genau das macht ihn deutlich aussagekräftiger als viele klassische Vergleiche.
ARC AGI 3 Benchmark: Der Vergleich, der alles verändert
Seine volle Wirkung entfaltet der Benchmark im direkten Vergleich. Menschen erreichen einen Score von 100 Prozent. Klassische KI-Modelle liegen unter 1 Prozent. Allein dieser Unterschied ist deutlich. Wirklich interessant wird es mit der dritten Kategorie. Ein agentisches System, konkret das Agentica SDK, erreicht 36,08 Prozent.

Diese Zahlen stehen nicht isoliert nebeneinander. Sie zeigen eine klare Verschiebung. Der Abstand zwischen Mensch und Modell ist extrem, während gleichzeitig auch der Sprung vom Modell zum agentischen System groß ist. Das macht den Unterschied sichtbar. Es geht hier nicht um kleine Verbesserungen.
Zur Einordnung:
| Systemtyp | Ergebnis im Benchmark |
| Mensch | 100 % |
| KI-Modelle | < 1 % |
| Agentica SDK | 36,08 % |
Der Vergleich macht deutlich, dass es um mehr geht als Leistungsunterschiede. Es geht um unterschiedliche Kategorien von Leistungsfähigkeit. Modelle scheitern fast vollständig. Ein agentisches System kann einen relevanten Teil der Aufgaben lösen. Gleichzeitig wird hier der entscheidende Hinweis deutlich. Hier wirkt eine strukturelle Differenz.
ARC AGI 3 Benchmark: Warum diese Zahlen eine klare Aussage treffen
Die entscheidende Aussage steckt in der Größenordnung der Unterschiede. Es geht nicht um eine Steigerung von 10 auf 20 Prozent. Der Sprung erfolgt von unter 1 Prozent auf über 36 Prozent. Außerdem zeigt sich daran, dass das Problem tiefer liegt. Es geht nicht um Feinabstimmung.
Hier wird eine Grenze sichtbar. Klassische Modelle sind in diesem Kontext nicht dafür ausgelegt, komplexe Probleme stabil zu lösen. Gleichzeitig zeigt das bessere Ergebnis des Agentica SDK, dass sich diese Grenze verschieben lässt. Der Hebel liegt nicht im Modell allein. Der Hebel liegt in der Art, wie es eingesetzt wird.
Genau dadurch wird der Benchmark relevant. Er liefert mehr als Zahlen. Er macht sichtbar, wo Leistung tatsächlich entsteht. Nicht nur im Modell selbst. Sondern in der Struktur, in der es arbeitet. Genau das ist die eigentliche Aussage von ARC AGI 3. Der Unterschied zwischen Scheitern und funktionierender Problemlösung entsteht durch Organisation.
Warum KI-Modelle im ARC AGI 3 Benchmark scheitern
Antworten ohne Struktur
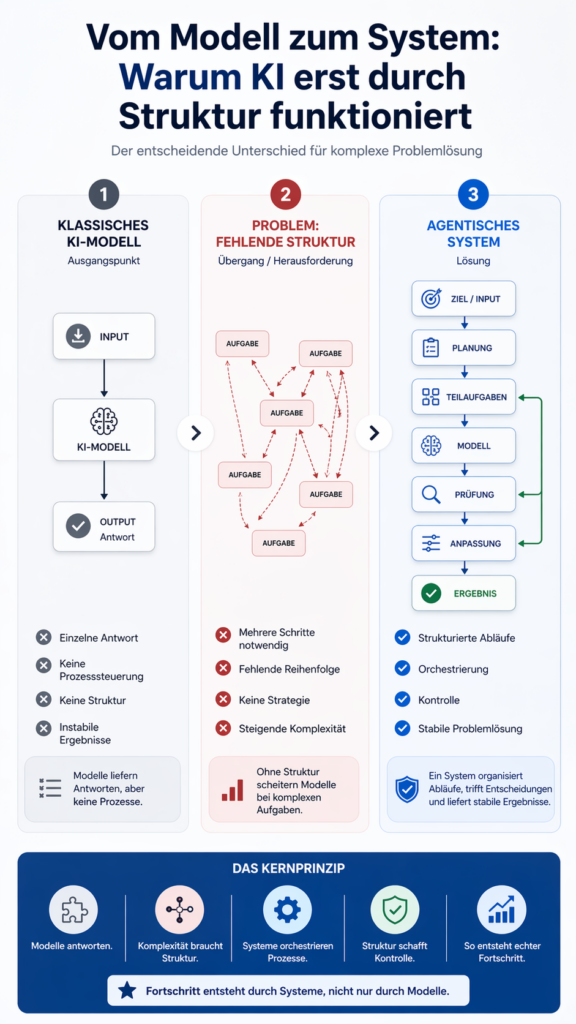
Klassische KI-Modelle sind darauf ausgelegt, Eingaben zu verarbeiten und darauf eine passende Ausgabe zu erzeugen. Genau darin liegt ihre Stärke. Genau hier liegt auch ihre Grenze. Sie liefern Antworten, aber sie organisieren keine Lösungsprozesse. Dieser Unterschied wirkt klein. Im Kontext des ARC AGI 3 Benchmarks ist er entscheidend.
Solange eine Aufgabe aus einem einzelnen Schritt besteht, funktioniert dieses Prinzip gut. Eine präzise Antwort reicht aus. Sobald mehrere Schritte notwendig werden, ändert sich die Situation. Es geht dann nicht mehr nur um eine richtige Aussage. Es geht darum, einen Lösungsweg aufzubauen. Genau dieser Teil fehlt den Modellen. Sie erzeugen Ergebnisse, aber sie steuern den Weg dorthin nicht.
Hier wird das Problem sichtbar. Aufgaben mit mehreren Entscheidungen oder klarer Abfolge lassen sich so nicht stabil lösen. Die Leistung fällt nicht langsam ab. Sie bricht ein. Genau deshalb liegen klassische Modelle im ARC AGI 3 Benchmark unter einem Prozent.
Fehlende Steuerung und Kontrolle
Der nächste Punkt verstärkt dieses Problem. Klassische Modelle arbeiten ohne klare Prozessführung. Sie bekommen eine Eingabe und erzeugen eine Ausgabe. Dazwischen fehlt eine strukturierte Steuerung. Es gibt keine festen Schritte. Es gibt keine Instanz, die den Ablauf überprüft.
Das hat direkte Folgen. Komplexe Aufgaben werden nicht in Teilprobleme zerlegt. Sie werden als Ganzes verarbeitet. Gleichzeitig fehlt eine Kontrolle über den Lösungsweg. Fehler bleiben unentdeckt und setzen sich dadurch im weiteren Verlauf fort. Es gibt keinen Mechanismus, der eingreift.
In der Praxis zeigt sich das deutlich. Ein Modell kann einzelne Teile einer Aufgabe korrekt erfassen, doch es hat Schwierigkeiten, diese Teile sauber zusammenzuführen. Der Ablauf wird instabil. Ergebnisse widersprechen sich. Prozesse brechen ab. Dadurch kommt es im Benchmark dazu, dass selbst lösbare Aufgaben nicht abgeschlossen werden.
Komplexität als strukturelles Problem
Hier verdichten sich die einzelnen Punkte zu einem größeren Zusammenhang. Fehlende Struktur und fehlende Steuerung wirken zusammen. Komplexität wird dadurch zum eigentlichen Problem. Dabei geht es nicht nur um Schwierigkeit. Es geht um Aufbau.
Sobald mehrere Schritte, Abhängigkeiten oder Anpassungen notwendig sind, steigt die Anforderung an die Organisation. Genau hier fehlt den Modellen eine Grundlage. Ohne externe Struktur müssen sie alles gleichzeitig verarbeiten. Es fehlen stabile Zwischenzustände, und dadurch entsteht Unsicherheit im Ablauf. Außerdem fehlt eine klare Reihenfolge, wodurch Prozesse nicht sauber aufgebaut werden können. Gleichzeitig existiert keine Strategie über mehrere Schritte hinweg, was die Problemlösung zusätzlich erschwert.
Die Folge ist eindeutig. Komplexität wird nicht reduziert. Sie trifft direkt auf das System. Das erklärt auch die extrem niedrigen Benchmark-Werte. Diese Werte zeigen keine generelle Unfähigkeit. Sie zeigen eine Grenze im Systemaufbau. Modelle sind in dieser Form nicht dafür gemacht, komplexe Probleme eigenständig zu strukturieren.
Genau das legt der Benchmark offen. Er zeigt, was Modelle leisten können. Vor allem zeigt er, was ihnen fehlt, sobald Aufgaben über einfache Antworten hinausgehen.
Agent-Harnesses im ARC AGI 3 Benchmark: Was hier anders funktioniert
Eine strukturierende Schicht statt isolierter Nutzung
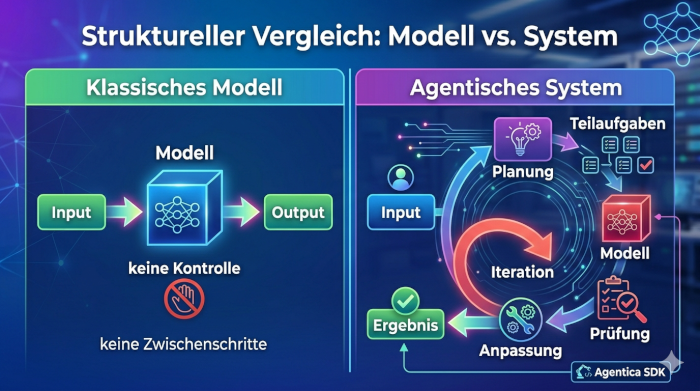
Ein Agent-Harness ist keine neue Form von KI. Er ist eine zusätzliche Ebene. Genau diese Ebene verändert den Umgang mit einem Modell grundlegend. Ein klassisches Modell reagiert direkt auf eine Eingabe. Ein agentisches System bettet das Modell in eine strukturierte Umgebung ein. Diese Umgebung übernimmt die Organisation des Lösungsprozesses.
Das verändert die Rolle des Modells. Das Modell steht nicht mehr allein im Zentrum, sondern wird in einen größeren Zusammenhang eingebettet. Gleichzeitig wird es Teil eines Ablaufs, der mehrere Schritte umfasst. Dadurch beantwortet es nicht einfach nur eine Frage, sondern arbeitet innerhalb klar definierter Prozesse. Diese Schritte bauen aufeinander auf. Genau das bringt Ordnung in komplexe Aufgaben. Aus einem unübersichtlichen Problem entsteht eine Abfolge von Teilproblemen.
Hier liegt der entscheidende Punkt. Das Modell bleibt bestehen. Es wird nicht ersetzt. Es bleibt die Instanz, die Informationen verarbeitet. Der Unterschied entsteht durch Steuerung. Das Modell arbeitet nicht mehr isoliert. Es wird gezielt eingesetzt. Genau diese zusätzliche Schicht erklärt, warum ein System wie das Agentica SDK im ARC AGI 3 Benchmark deutlich besser abschneidet als ein Modell allein.
Zusammenspiel von Modell, Ablauf und Werkzeugen
Ein Agent-Harness funktioniert durch Zusammenspiel, und es gibt kein einzelnes Element, das alles verbessert. Das Modell ist nur ein Teil. Hinzu kommt eine klare Struktur. Hinzu kommt die Fähigkeit, Aufgaben zu organisieren und zu steuern.
Probleme werden nicht mehr auf einmal gelöst. Sie werden aufgeteilt. Das System entscheidet, welcher Schritt als nächstes sinnvoll ist. Es setzt das Modell gezielt ein. Dadurch entsteht Kontrolle. Genau das fehlt klassischen Modellen.
Diese Struktur wirkt direkt auf die Ergebnisse. Fehler werden nicht einfach weitergegeben. Sie können erkannt werden. Sie können umgangen werden. Der Lösungsweg bleibt nachvollziehbar. Er wird stabil. Im Benchmark wird das klar sichtbar. Isolierte Modelle lösen fast keine Aufgaben. Ein agentisches System erreicht einen deutlich höheren Anteil.
Die Verbesserung entsteht nicht durch mehr Leistung im Modell. Sie entsteht durch bessere Organisation. Das System nutzt das vorhandene Potenzial effektiver. Genau dadurch wird Problemlösung stabil und wiederholbar.
Vom Antworten zum Handeln
Der wichtigste Unterschied zeigt sich in der Rolle des Systems. Ein klassisches Modell antwortet. Es verarbeitet eine Eingabe und liefert ein Ergebnis. Ein agentisches System arbeitet anders. Statt einzelner Antworten entsteht ein Prozess, der aktiv ausgeführt wird. Innerhalb dieses Ablaufs trifft das System Entscheidungen und reagiert auf Zwischenergebnisse. Gleichzeitig passt es sein Vorgehen kontinuierlich an, wodurch der Lösungsweg stabil bleibt.
Genau das verändert die Dynamik. Es bleibt nicht bei einer einzelnen Interaktion. Es entsteht ein Ablauf. Dieser Ablauf entwickelt sich Schritt für Schritt. Das System reagiert auf Zwischenergebnisse. Es bestimmt den nächsten Schritt. Es steuert den gesamten Lösungsweg.
Hier wird der Unterschied greifbar. Aus einer passiven Antwort wird ein aktiver Prozess. Genau das macht komplexe Aufgaben überhaupt erst bearbeitbar.
Im ARC AGI 3 Benchmark zeigt sich dieser Effekt klar. Aufgaben mit mehreren Schritten scheitern bei klassischen Modellen. In einem agentischen System werden sie zumindest teilweise lösbar. Der Grund liegt nicht im Modell selbst. Der Grund liegt im Rahmen, in dem es arbeitet.
Damit wird die Wirkung von Agent-Harnesses verständlich. Sie verändern nicht die Fähigkeiten des Modells. Sie verändern die Nutzung dieser Fähigkeiten. Genau hier liegt der entscheidende Unterschied zur klassischen KI-Nutzung. Und genau das erklärt, warum agentische Systeme im Benchmark deutlich besser abschneiden.
Modell vs System: Der entscheidende Unterschied in der KI
Vom Einzelwerkzeug zum Zusammenspiel
Der zentrale Unterschied zwischen klassischen KI-Modellen und agentischen Systemen liegt nicht in der reinen Leistung des Modells. Er liegt in der Einbettung. Bisher stand fast immer das Modell im Mittelpunkt. Die typische Frage: Welches Modell ist besser, schneller oder genauer? Genau hier greift die Betrachtung zu kurz.
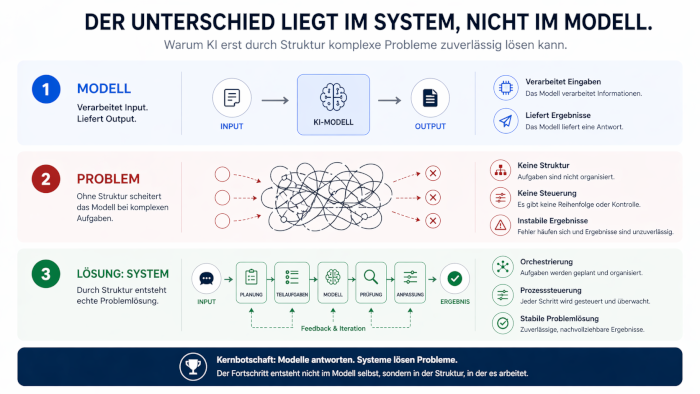
Leistung entsteht nicht isoliert. Ein starkes Modell bleibt begrenzt, wenn es ohne Struktur arbeitet. Erst in einer klaren Umgebung entfaltet sich sein Potenzial. Diese Umgebung organisiert Abläufe. Sie strukturiert Entscheidungen. Genau dadurch entsteht ein größerer Nutzen. Der Fokus verschiebt sich. Weg vom einzelnen Werkzeug. Hin zum Gesamtsystem.
Diese Verschiebung verändert die Bewertung von KI. Es reicht nicht mehr, den Output zu vergleichen. Entscheidend ist, wie gut ein System ein Problem als Ganzes bearbeitet. Genau das macht der ARC AGI 3 Benchmark sichtbar. Er prüft nicht nur Antworten. Er prüft Problemlösung. Damit rückt das System in den Mittelpunkt.
Orchestrierung als entscheidender Faktor
Hier kommt ein zentraler Begriff ins Spiel: Orchestrierung. Ein Modell verarbeitet Inhalte, während ein System den Ablauf organisiert. Das System legt fest, welche Schritte notwendig sind, und schafft damit Struktur im Ablauf. Anschließend bestimmt es die Reihenfolge der einzelnen Schritte, wodurch Komplexität reduziert wird. Gleichzeitig werden Zwischenergebnisse gezielt weiterverwendet, sodass der Prozess effizient bleibt. Genau hier verändert sich die Rolle der KI.

Der Unterschied ist klar. Ein Modell liefert eine Antwort. Ein System führt einen Prozess aus. Genau das ist der funktionale Kern. Aufgaben werden nicht mehr als unstrukturierte Eingabe behandelt. Sie werden zerlegt. Sie werden gesteuert. Genau dadurch entsteht Kontrolle.
Diese Kontrolle wirkt sich direkt auf die Ergebnisse aus. Antworten werden konsistenter. Fehler bleiben nicht unbemerkt. Der Lösungsweg wird nachvollziehbar. Genau diese Struktur erklärt die besseren Ergebnisse im Benchmark. Es liegt nicht an einem stärkeren Modell. Es liegt am System, das Komplexität beherrschbar macht.
Ein sichtbarer Trend in der Praxis
Diese Entwicklung steht nicht für sich allein. Sie zeigt sich bereits in der Praxis. Die Nutzung von CLI-Agenten und agentischen Tools nimmt zu. Genau hier verschiebt sich der Fokus sichtbar. Nutzer arbeiten weniger mit einzelnen Tools. Sie arbeiten mit Systemen, die Abläufe organisieren.
Diese Systeme folgen demselben Prinzip wie ein Agent-Harness. Modell, Struktur und Ablauf greifen ineinander. Der Nutzer definiert ein Ziel. Das System übernimmt die Umsetzung. Es arbeitet in mehreren Schritten. Es organisiert den Prozess eigenständig.
Hier schließen sich Theorie und Praxis. Der Benchmark liefert den Beleg. Die aktuellen Tools zeigen die Anwendung. Zusammen ergibt sich ein klares Bild. Fortschritt entsteht nicht mehr nur durch bessere Modelle. Fortschritt entsteht durch bessere Systeme. Genau darin liegt der eigentliche Paradigmenwechsel.
Warum der ARC AGI 3 Benchmark für Unternehmen entscheidend ist
Antworten sind kein Geschäftsprozess
Die Ergebnisse des ARC AGI 3 Benchmarks zeigen mehr als eine technische Schwäche. Sie betreffen direkt den Einsatz im Unternehmen. Der Kern ist einfach. Eine einzelne Antwort ist kein Prozess.
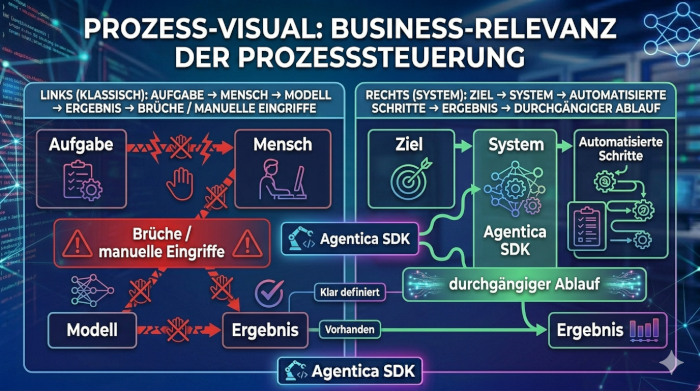
Im Alltag geht es selten um eine isolierte Frage. Es geht um Abläufe. Aufgaben bestehen aus mehreren Schritten. Entscheidungen greifen ineinander. Abhängigkeiten müssen berücksichtigt werden. Ein Modell kann einzelne Teile unterstützen. Es übernimmt jedoch nicht den gesamten Ablauf. Genau hier entsteht die Lücke zwischen theoretischer Leistung und praktischer Nutzung.
Diese Lücke erklärt viele Enttäuschungen in der Praxis. Reine Modellnutzung liefert Ergebnisse, aber keine vollständigen Prozesse. Unternehmen brauchen mehr. Sie brauchen Systeme, die Aufgaben strukturieren und vollständig ausführen. Genau das macht der Benchmark sichtbar. Modelle allein reichen dafür nicht aus. Erst mit einer zusätzlichen Struktur entsteht ein nutzbarer Ablauf.
Automatisierung entsteht durch Struktur
Agentische Systeme setzen genau an diesem Punkt an. Sie erzeugen nicht nur Inhalte. Sie organisieren Abläufe. Genau das verändert den Einsatz von KI im Unternehmen. Tools wie CLI-Agenten zeigen, wie sich dieser Ansatz umsetzen lässt. Sie koordinieren Prozesse. Sie arbeiten Schritt für Schritt.
Ein System erkennt, welche Schritte notwendig sind. Es bringt diese Schritte in eine Reihenfolge. Es nutzt das Modell gezielt für einzelne Aufgaben. Genau dadurch entsteht echte Automatisierung. Aufgaben werden nicht mehr nur begleitet. Sie werden übernommen.
Hier liegt die direkte Wirkung. Prozesse laufen stabiler, und gleichzeitig sinkt der Aufwand. Gleichzeitig wird Skalierung möglich. Abläufe hängen nicht mehr von manuellen Eingriffen ab. Genau das entscheidet darüber, ob KI ein Hilfsmittel bleibt oder ein produktiver Bestandteil wird.
Der Benchmark liefert dafür die Grundlage. Die besseren Ergebnisse agentischer Systeme zeigen klar, dass Struktur einen messbaren Unterschied macht. Es geht nicht um Theorie. Es geht um konkrete Auswirkungen auf Problemlösung.
Wettbewerb verschiebt sich auf die Systemebene
Mit dieser Entwicklung verändern sich die Anforderungen. Bisher lag der Fokus auf Tools und Modellen. Diese Sicht greift zu kurz. Entscheidend wird, wie diese Elemente zusammenarbeiten.
Systemdesign rückt in den Mittelpunkt. Es geht darum, eine funktionierende Struktur aufzubauen. Das Modell ist ein Teil davon. Wichtiger wird, wie Abläufe organisiert sind. Orchestrierung, Steuerung und Integration bestimmen die Qualität.
Das hat direkte Folgen für den Wettbewerb. Unternehmen, die nur Tools einsetzen, stoßen schnell an Grenzen. Sobald Prozesse komplex werden, reicht das nicht mehr aus. Unternehmen mit klaren Systemen arbeiten anders. Dadurch lösen diese Systeme Aufgaben stabil und nachvollziehbar. Gleichzeitig arbeiten sie effizient, weil Abläufe klar strukturiert sind. Außerdem lassen sich diese Prozesse skalieren, da sie nicht mehr von manuellen Eingriffen abhängen.
Hier wird der Unterschied strategisch. Leistung entsteht nicht im Modell allein. Sie entsteht im System. Genau das zeigt der Benchmark. Für Unternehmen bedeutet das eine klare Richtung. Wer KI erfolgreich einsetzen will, muss Systeme bauen. Nicht nur Tools nutzen.
Grenzen des Benchmarks – was man nicht falsch verstehen darf
Ein Benchmark ist kein universeller Beweis
Die Ergebnisse des ARC AGI 3 Benchmarks wirken eindeutig. Genau hier entsteht schnell ein Denkfehler. Diese Ergebnisse gelten für einen klar definierten Kontext. Sie lassen sich nicht automatisch auf alle Formen von KI übertragen.
Ein Benchmark zeigt immer nur einen Ausschnitt der Realität. Er misst eine bestimmte Fähigkeit unter festen Bedingungen. Im Fall von ARC AGI 3 geht es um Problemlösung in einer konkreten Form. Daraus lässt sich ableiten, dass Modelle in genau diesem Umfeld schwach abschneiden. Daraus lässt sich aber nicht ableiten, dass sie in jeder anderen Anwendung versagen.
Genau das ist wichtig für die Einordnung. Der Benchmark liefert zwar ein starkes Signal, jedoch keinen universellen Beweis. Wer diesen Unterschied ignoriert, zieht zu weitgehende Schlüsse. Genau hier entstehen Übertreibungen.
Begrenzte Einblicke in die Methodik
Ein weiterer Punkt liegt in der Tiefe der verfügbaren Informationen. Die Quelle zeigt klare Ergebnisse. Sie beschreibt zentrale Unterschiede. Gleichzeitig fehlen detaillierte Einblicke in die genaue Methodik. Die interne Struktur des Benchmarks und des Agentica SDK wird nicht vollständig offengelegt.
Das hat direkte Folgen für die Interpretation. Aussagen müssen sauber formuliert werden. Der Unterschied zwischen Modellen und agentischen Systemen lässt sich klar benennen. Er ergibt sich aus den Ergebnissen. Darüber hinaus sollte nichts angenommen werden, was nicht belegt ist.
Hier liegt eine klare Grenze. Wer diese Grenze respektiert, gewinnt an Glaubwürdigkeit. Wer sie überschreitet, landet schnell im Spekulativen. Gerade bei einem Thema mit viel Aufmerksamkeit ist diese Trennung entscheidend.
Fortschritt, aber kein Durchbruch
Die Zahlen selbst müssen ebenfalls richtig eingeordnet werden. 36,08 Prozent sind ein deutlicher Fortschritt gegenüber unter einem Prozent. Gleichzeitig bleibt der Abstand zum menschlichen Niveau groß. 100 Prozent stehen weiterhin als Referenz.
Genau hier braucht es eine klare Sicht. Agentische Systeme schneiden besser ab. Dennoch lösen diese Systeme das Problem nicht vollständig, sondern stoßen weiterhin an Grenzen. Stattdessen zeigen sie eine klare Richtung für die weitere Entwicklung. Gleichzeitig liefern sie keine fertige Lösung, sondern lediglich einen nächsten Schritt. Wer das übersieht, überschätzt den aktuellen Stand.
Eine nüchterne Betrachtung bringt Klarheit. Der Benchmark zeigt, dass Struktur einen großen Einfluss hat. Gleichzeitig zeigt er, dass die Entwicklung noch am Anfang steht. Es gibt Fortschritt. Es gibt keinen endgültigen Durchbruch.
Diese Einordnung stärkt die Aussage des Artikels. Der Benchmark liefert keine abschließenden Antworten. Er zeigt eine Entwicklungslinie. Genau darin liegt sein Wert. Er macht sichtbar, wohin sich KI-Systeme bewegen, ohne die bestehenden Grenzen auszublenden.
ARC AGI 3 Benchmark: Was sich jetzt verändert
Vom Werkzeug zum System
Die Ergebnisse des ARC AGI 3 Benchmarks stehen nicht für sich allein. Sie sind Teil einer Entwicklung, die bereits läuft. Genau hier beginnt der eigentliche Wandel. KI bewegt sich weg vom Werkzeug. Sie entwickelt sich zum System.
Bisher wurde KI vor allem punktuell eingesetzt. Texte schreiben, Fragen beantworten, Inhalte analysieren. Diese Nutzung bleibt auf einzelne Eingriffe begrenzt. Sie unterstützt. Sie übernimmt jedoch keinen vollständigen Ablauf.
Mit agentischen Systemen verschiebt sich diese Rolle. KI organisiert Prozesse. Sie arbeitet nicht mehr nur einzelne Schritte ab. Sie verfolgt ein Ziel über mehrere Schritte hinweg. Genau das verändert die Nutzung grundlegend. Der Fokus liegt nicht mehr auf der einzelnen Antwort. Der Fokus liegt auf dem gesamten Ablauf.
Hier wird die Bedeutung klar. Sobald KI als System gedacht wird, verändert sich ihr Einsatzbereich. Aufgaben werden nicht nur unterstützt. Sie werden übernommen. Genau das erklärt, warum agentische Ansätze im Benchmark besser abschneiden. Sie folgen bereits dieser Logik.
Erste Anzeichen in der Praxis
Diese Entwicklung ist längst sichtbar. Sie zeigt sich in aktuellen Tools. Die Nutzung von CLI-Agenten nimmt zu. Genau hier verändert sich die Arbeitsweise. Nutzer konfigurieren nicht mehr jeden Schritt einzeln. Systeme übernehmen die Struktur.
Auch automatisierte Workflows zeigen diesen Trend. Systeme bewerten Situationen. Sie entscheiden, welche Schritte sinnvoll sind. Sie führen diese Schritte aus. Der Nutzer gibt nicht mehr jede Anweisung im Detail vor. Er definiert den Rahmen. Innerhalb dieses Rahmens arbeitet das System.
Genau das bestätigt die Ergebnisse des Benchmarks. Die bessere Leistung agentischer Systeme ist kein Einzelfall. Sie spiegelt eine Entwicklung, die bereits im Einsatz ist. Der Unterschied zwischen Modell und System wird damit greifbar. Er bleibt nicht abstrakt. Er wird sichtbar.
Die Richtung der nächsten Entwicklung
Aus dieser Perspektive ergibt sich eine klare Richtung. Der Fokus verschiebt sich weiter. Weg von reiner Modellleistung. Hin zur Struktur, in der diese Leistung genutzt wird. Modelle bleiben relevant. Sie sind jedoch nicht mehr der alleinige Maßstab.
Zukünftige Systeme werden anders bewertet. Entscheidend wird, wie gut sie Prozesse organisieren. Wie stabil sie Abläufe steuern. Wie zuverlässig sie Entscheidungen treffen. Genau hier entsteht Qualität. Die Generierung von Inhalten allein reicht nicht mehr aus.
Diese Einordnung bleibt bewusst nüchtern. Der Benchmark zeigt keine fertige Lösung. Er zeigt eine Richtung. Agentische Systeme sind stärker als klassische Modelle. Sie erreichen jedoch noch nicht das Niveau menschlicher Problemlösung.
Trotzdem markiert diese Entwicklung einen Wendepunkt. Fortschritt entsteht nicht mehr nur durch bessere Modelle. Fortschritt entsteht durch bessere Systeme. Genau dieser Wandel hat begonnen.
Fazit
Der ARC AGI 3 Benchmark zeigt klar eine Entwicklung, die leicht übersehen wird. Klassische KI-Modelle stoßen an klare Grenzen, sobald Aufgaben mehr verlangen als eine einzelne Antwort. Genau hier zeigt sich das Problem. Die extrem niedrigen Ergebnisse bedeuten nicht, dass diese Modelle unbrauchbar sind. Sie zeigen, dass sie für strukturierte Problemlösung allein nicht ausreichen.
Im direkten Vergleich wird der Unterschied greifbar. Agentische Systeme erreichen deutlich bessere Ergebnisse, obwohl sie auf denselben Modellen basieren. Genau das ist der entscheidende Punkt. Es geht nicht um das Modell selbst. Es geht um die Struktur, in der es arbeitet. Erst eine organisierte Umgebung macht aus isolierter Verarbeitung einen funktionierenden Lösungsprozess.
Damit verschiebt sich die Perspektive auf KI. Der Fokus auf Modellvergleiche reicht nicht aus, wenn es um reale Anwendungen geht. Entscheidend ist etwas anderes. Wie gut ein System Aufgaben zerlegt, wie stabil es Abläufe steuert und wie zuverlässig es Ergebnisse zusammenführt. Genau hier entsteht echte Leistungsfähigkeit.
Die zentrale Erkenntnis ist klar. Fortschritt in der KI entsteht nicht nur durch bessere Modelle. Er entsteht vor allem durch bessere Systeme. Wer KI sinnvoll einsetzen will, muss diesen Unterschied verstehen. Es reicht nicht, das stärkste Modell auszuwählen. Entscheidend ist, wie dieses Modell in ein funktionierendes Gesamtsystem eingebunden wird.
Der ARC AGI 3 Benchmark liefert keinen endgültigen Beweis. Er liefert einen klaren Hinweis. Die Bewertung von KI verändert sich. Weg vom einzelnen Modell. Hin zur Qualität des Systems.
FAQ
Was ist der ARC AGI 3 Benchmark einfach erklärt?
Ein Test, der misst, ob KI Probleme strukturiert lösen kann, statt nur Antworten zu liefern.
Warum ist der ARC AGI 3 Benchmark wichtig?
Weil er zeigt, dass reine KI-Modelle bei komplexen Aufgaben versagen und Systeme deutlich besser funktionieren.
Was ist der Unterschied zwischen KI-Modell und KI-System?
Ein Modell gibt Antworten. Ein System organisiert Prozesse und löst Aufgaben Schritt für Schritt.
Warum schneiden KI-Modelle im ARC AGI 3 Benchmark schlecht ab?
Weil ihnen Struktur und Steuerung fehlen, um komplexe Probleme stabil zu lösen.
Was sind agentische Systeme?
KI-Systeme, die Aufgaben in Schritte zerlegen, Entscheidungen treffen und Prozesse eigenständig ausführen.
Was bedeutet das für Unternehmen?
Erfolg entsteht nicht durch Tools, sondern durch Systeme, die komplette Abläufe automatisieren.
Ist der ARC AGI 3 Benchmark ein Beweis für bessere KI?
Nein. Er zeigt eine Richtung, aber keinen endgültigen Durchbruch.





