

Sub-Agent Architektur erklärt: KI-Probleme lösen
Die Sub-Agent Architektur entwickelt sich zu einem zentralen Ansatz, um eines der größten Probleme moderner KI-Systeme zu lösen. Künstliche Intelligenz hat in den letzten Jahren enorme Fortschritte gemacht und ist heute in der Lage, komplexe Aufgaben zu analysieren, Inhalte zu erstellen und Prozesse zu automatisieren. Gleichzeitig wird jedoch ein grundlegendes Problem immer deutlicher: Je leistungsfähiger diese Systeme werden, desto schwieriger wird es, sie zuverlässig zu steuern. Besonders bei längeren Interaktionen oder komplexen Workflows stoßen viele Anwendungen an ihre Grenzen.
Ein zentraler Grund dafür liegt im Umgang mit Kontext. Klassische KI-Nutzung basiert häufig auf langen Eingaben und fortlaufenden Dialogen. Mit jeder zusätzlichen Information steigt jedoch die Komplexität im Hintergrund. Relevante und irrelevante Inhalte vermischen sich zunehmend, Entscheidungen werden unklarer, und die Ergebnisse verlieren an Konsistenz. Dieses Phänomen wird als Kontextverschmutzung bezeichnet – und es gehört zu den Hauptursachen dafür, dass viele KI-Workflows heute nicht stabil funktionieren.
Für Unternehmen wird dieses Problem schnell kritisch. Sobald Aufgaben mehrstufig werden oder unterschiedliche Informationen kombiniert werden müssen, nimmt die Qualität der Ergebnisse spürbar ab. Automatisierungen, die auf dem Papier sinnvoll erscheinen, liefern in der Praxis oft unzuverlässige Resultate. Die Folge sind steigende Kosten, ineffiziente Prozesse und eine wachsende Skepsis gegenüber dem Einsatz von KI im operativen Alltag.
Genau an diesem Punkt setzt eine neue Entwicklung an: die Sub-Agent-Architektur. Anstatt ein einzelnes System mit immer mehr Kontext zu überladen, werden Aufgaben gezielt strukturiert und auf mehrere spezialisierte Einheiten verteilt. Dieser Ansatz verändert grundlegend, wie KI-Systeme aufgebaut und eingesetzt werden – und könnte der entscheidende Schritt sein, um komplexe KI-Anwendungen erstmals wirklich skalierbar und stabil nutzbar zu machen.
Warum klassische KI ohne Sub-Agent Architektur am Kontextproblem scheitert
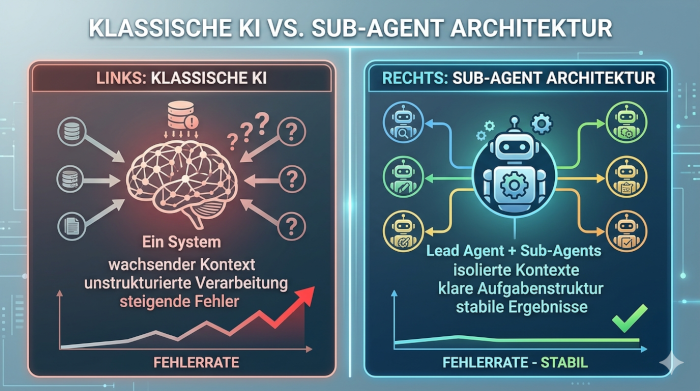
Das Problem wachsender Kontextfenster
Moderne KI-Systeme arbeiten auf Basis eines sogenannten Kontextfensters. Vereinfacht gesagt handelt es sich dabei um den „Gedächtnisbereich“, in dem alle bisherigen Eingaben, Anweisungen und Informationen gespeichert werden, die das System für seine nächste Antwort berücksichtigt. Mit jeder weiteren Interaktion wächst dieses Kontextfenster kontinuierlich. Zu Beginn ist das unproblematisch, da die Informationen noch klar strukturiert und unmittelbar relevant sind. Doch je länger die Interaktion andauert, desto mehr Inhalte sammeln sich an – und genau an diesem Punkt beginnt die eigentliche Herausforderung.
Der Kontext wird zunehmend unübersichtlich. Informationen, die zu Beginn wichtig waren, bleiben weiterhin enthalten, obwohl sie für die aktuelle Aufgabe längst keine Rolle mehr spielen. Gleichzeitig kommen neue Inhalte hinzu, die nicht immer sauber eingeordnet werden können. Für die KI entsteht dadurch ein immer dichteres Geflecht an Daten, das bei jeder Antwort berücksichtigt werden muss.
Die Folge ist ein schleichender Verlust an Klarheit. Die KI verliert an Fokus, weil sie nicht mehr eindeutig priorisieren kann, welche Informationen entscheidend sind. Statt sich präzise auf die aktuelle Aufgabe zu konzentrieren, wird sie von Altinformationen beeinflusst. Antworten werden dadurch weniger klar, teilweise widersprüchlich oder thematisch unscharf. Genau hier zeigt sich die erste grundlegende Grenze klassischer KI-Nutzung.
Kontextverschmutzung als Kernproblem ohne Sub-Agent Architektur
Dieses Phänomen wird als Kontextverschmutzung bezeichnet. Gemeint ist damit die Ansammlung irrelevanter, veralteter oder widersprüchlicher Informationen innerhalb des Kontextfensters. Entscheidend ist dabei nicht nur die Menge der Daten, sondern vor allem deren Qualität und Struktur.

In der Praxis bedeutet das: Die KI kann nicht zuverlässig unterscheiden, welche Informationen aktuell relevant sind und welche nicht. Frühere Annahmen, Zwischenergebnisse oder missverständliche Eingaben bleiben im System bestehen und beeinflussen neue Antworten. Dadurch entstehen Fehler, die sich im weiteren Verlauf nicht nur fortsetzen, sondern häufig sogar verstärken.
Besonders kritisch wird diese Dynamik bei komplexen Aufgaben. Sobald mehrere Schritte notwendig sind oder unterschiedliche Informationen miteinander kombiniert werden müssen, steigt die Wahrscheinlichkeit für Inkonsistenzen deutlich. Die KI trifft ihre Entscheidungen dann auf Basis eines „verschmutzten“ Kontextes – und genau das führt zu ungenauen oder fehlerhaften Ergebnissen.
Für den Nutzer ist dieses Verhalten oft schwer nachvollziehbar. Die Qualität der Antworten scheint plötzlich zu schwanken, obwohl sich am Modell selbst nichts verändert hat. Tatsächlich liegt die Ursache nicht in der Leistungsfähigkeit der KI, sondern in der Qualität des Kontextes, auf den sie zugreift.
Kosten- und Effizienzprobleme durch große Kontexte
Neben der inhaltlichen Qualität hat ein wachsender Kontext eine weitere direkte Auswirkung: steigende Kosten und sinkende Effizienz. Jeder zusätzliche Kontext muss bei der Verarbeitung berücksichtigt werden, was den Rechenaufwand pro Anfrage erhöht.
Je größer der Kontext wird, desto aufwendiger gestaltet sich jede einzelne Anfrage. Das führt nicht nur zu höheren Kosten, sondern auch zu längeren Antwortzeiten. Systeme reagieren langsamer, und ihre wirtschaftliche Nutzung wird zunehmend schwieriger – insbesondere im Unternehmenskontext, in dem viele Anfragen parallel verarbeitet werden müssen.
Hinzu kommt ein strukturelles Ungleichgewicht: Mehr Kontext führt nicht automatisch zu besseren Ergebnissen. Im Gegenteil, ab einem bestimmten Punkt verschlechtert sich die Qualität, obwohl der Aufwand weiter steigt. Es entsteht eine Situation, in der Ressourcen zunehmen, der tatsächliche Nutzen jedoch abnimmt.
Genau an dieser Stelle wird deutlich, warum klassische KI-Nutzung nicht beliebig skalierbar ist. Ohne eine klare Struktur zur Begrenzung und gezielten Organisation des Kontextes stoßen selbst leistungsfähige Modelle an ihre praktischen Grenzen.
Das Kontextproblem ohne Sub-Agent Architektur im Detail erklärt
Warum lange KI-Interaktionen instabil werden
Das zentrale Problem moderner KI-Systeme zeigt sich selten sofort, sondern entwickelt sich schrittweise über die Zeit. Zu Beginn einer Interaktion arbeitet die KI in der Regel präzise und nachvollziehbar. Die Eingaben sind klar formuliert, der Kontext ist überschaubar, und die Antworten wirken konsistent. Mit jeder weiteren Anfrage wächst jedoch nicht nur die Menge der Informationen, sondern auch deren Komplexität. Genau an diesem Punkt liegt die eigentliche Ursache der späteren Instabilität.
Die KI ist darauf angewiesen, alle relevanten Informationen innerhalb ihres Kontextfensters zu berücksichtigen. Gleichzeitig fehlt ihr jedoch die Fähigkeit, dauerhaft zuverlässig zwischen wichtigen und unwichtigen Inhalten zu unterscheiden. Statt gezielt zu priorisieren, behandelt sie den gesamten Kontext als potenziell relevant. Daraus entstehen schleichend Widersprüche, Überlagerungen und Fehlinterpretationen.
Die sichtbaren Symptome sind unklare oder widersprüchliche Antworten. Die eigentliche Ursache liegt jedoch tiefer: im fehlenden Mechanismus zur sauberen Trennung und Priorisierung von Informationen. Die KI „vergisst“ nicht aktiv, sondern wird von der wachsenden Menge an Daten überfordert. Die Folge ist ein schrittweiser Verlust an Konsistenz, der besonders bei längeren Interaktionen deutlich wird.
Auswirkungen auf komplexe Aufgaben und Workflows
Dieses Problem verstärkt sich deutlich, sobald KI nicht mehr nur für einzelne Antworten genutzt wird, sondern für komplexe Aufgaben. Mehrstufige Prozesse erfordern eine klare Struktur, da die einzelnen Schritte aufeinander aufbauen. Jede Entscheidung beeinflusst den nächsten Schritt, und jede Ungenauigkeit kann sich entlang des gesamten Workflows fortpflanzen.
Ohne eine saubere Trennung der Arbeitsschritte entsteht ein instabiles System. Informationen aus früheren Schritten bleiben im Kontext erhalten, auch wenn sie für den aktuellen Schritt keine Rolle mehr spielen. Gleichzeitig kommen neue Inhalte hinzu, die nicht immer korrekt eingeordnet werden. Das Ergebnis ist ein Prozess, der zunehmend an Klarheit verliert und schwerer steuerbar wird.
Die Symptome zeigen sich in fehlerhaften Zwischenergebnissen oder inkonsistenten Endresultaten. Die eigentliche Ursache ist jedoch strukturell: Es fehlt eine klare Organisation der Informationen. Die KI versucht, alle Inhalte gleichzeitig zu berücksichtigen, obwohl komplexe Aufgaben eine Aufteilung in einzelne, isolierte Schritte erfordern. Ohne diese Trennung brechen Workflows nicht abrupt zusammen, sondern werden schleichend unzuverlässig.
Warum klassische Lösungen das Problem nicht beheben
Auf den ersten Blick scheinen einfache Gegenmaßnahmen naheliegend. Der Kontext könnte regelmäßig gekürzt, irrelevante Inhalte entfernt oder die Interaktion komplett zurückgesetzt werden. Diese Ansätze greifen jedoch zu kurz, da sie lediglich die Symptome adressieren, nicht aber die zugrunde liegende Ursache.
Das Kürzen des Kontextes reduziert zwar die Datenmenge, löst aber nicht das grundlegende Problem der fehlenden Struktur. Es bleibt unklar, welche Informationen entfernt werden sollten und welche weiterhin relevant sind. Ein vollständiger Reset sorgt zwar kurzfristig für einen sauberen Ausgangspunkt, unterbricht jedoch gleichzeitig den gesamten Arbeitsprozess. Gerade bei komplexen Aufgaben ist das keine praktikable Lösung.
Die eigentliche Herausforderung liegt darin, dass klassische KI-Nutzung auf einem linearen Modell basiert: Eine einzelne Instanz verarbeitet alle Informationen innerhalb eines durchgehenden Kontextes. Dieses Modell stößt zwangsläufig an seine Grenzen, sobald Aufgaben komplexer und mehrstufig werden.
Die Konsequenz ist eindeutig. Es braucht keinen optimierten Umgang mit dem bestehenden System, sondern eine grundlegend andere Struktur. Eine Architektur, die Informationen gezielt trennt, Aufgaben klar aufteilt und den Kontext bewusst kontrolliert. Genau an diesem Punkt setzt die Sub-Agent-Architektur an, die das Problem nicht umgeht, sondern es auf struktureller Ebene löst.
Was ist eine Sub-Agent Architektur? Einfach erklärt
Der Lead Agent als zentrale Steuerinstanz
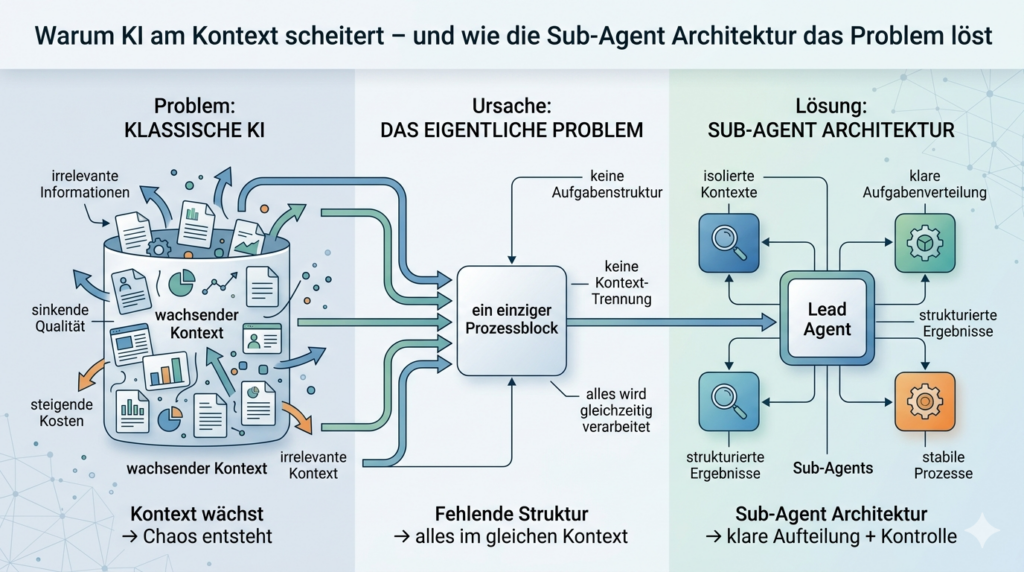
Eine Sub-Agent-Architektur basiert auf einer klaren Trennung von Rollen innerhalb eines KI-Systems. Im Zentrum steht der sogenannte Lead Agent, auch als Orchestrator bezeichnet. Seine Aufgabe besteht nicht darin, selbst Inhalte zu erzeugen oder Probleme direkt zu lösen, sondern den gesamten Prozess zu steuern. Er analysiert eine Aufgabe, zerlegt sie in sinnvolle Teilbereiche und legt fest, welche Schritte notwendig sind, um ein Ergebnis zu erreichen.
Diese Rolle ist entscheidend, weil sie Struktur in einen ansonsten schwer überschaubaren Prozess bringt. Anstatt dass ein einzelnes System versucht, alle Informationen gleichzeitig zu verarbeiten, übernimmt der Lead Agent die Koordination. Er sorgt dafür, dass jede Teilaufgabe klar definiert ist und innerhalb eines kontrollierten Rahmens bearbeitet wird. Dadurch entsteht eine saubere Trennung zwischen Planung und Ausführung – eine Voraussetzung für stabile und nachvollziehbare Ergebnisse.
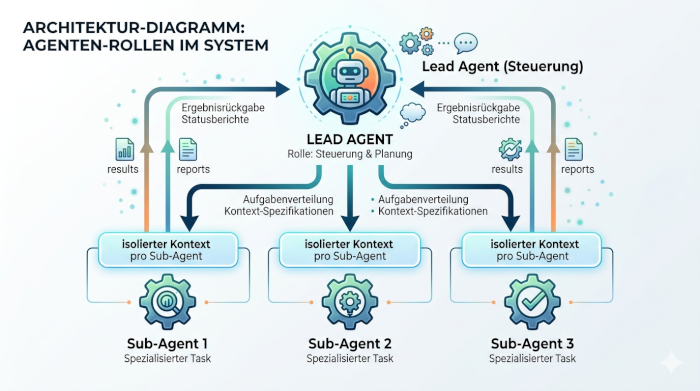
Sub-Agents als spezialisierte Ausführungseinheiten
Während der Lead Agent die Steuerung übernimmt, werden die eigentlichen Aufgaben von sogenannten Sub-Agents ausgeführt. Diese Sub-Agents sind spezialisierte Einheiten, die jeweils für eine klar abgegrenzte Aufgabe zuständig sind. Ein Sub-Agent kann beispielsweise Informationen recherchieren, ein anderer eine Analyse durchführen und ein weiterer die Ergebnisse strukturieren oder zusammenfassen.
Der entscheidende Punkt ist, dass jeder Sub-Agent ausschließlich mit den Informationen arbeitet, die für seine spezifische Aufgabe relevant sind. Er hat keinen Zugriff auf den gesamten Kontext des Systems, sondern agiert innerhalb eines klar begrenzten Rahmens. Dadurch wird verhindert, dass sich unnötige oder widersprüchliche Informationen ansammeln.
Diese Spezialisierung ermöglicht eine saubere Aufgabenteilung. Komplexe Probleme werden nicht mehr als ein zusammenhängender Block behandelt, sondern in einzelne, überschaubare Schritte zerlegt. Jeder dieser Schritte kann unabhängig und kontrolliert bearbeitet werden. Das verbessert nicht nur die Qualität der Ergebnisse, sondern macht den gesamten Prozess auch transparenter und leichter steuerbar.
Der grundlegende Unterschied zur klassischen KI-Nutzung
Der zentrale Unterschied zur klassischen Nutzung von KI liegt in der Art und Weise, wie Aufgaben verarbeitet werden. In traditionellen Ansätzen arbeitet ein einzelnes System mit einem durchgehenden Kontext. Es versucht, alle Informationen gleichzeitig zu berücksichtigen und daraus ein Ergebnis zu erzeugen. Dieses Modell funktioniert, solange die Aufgaben einfach sind und der Kontext überschaubar bleibt.
Sobald die Komplexität zunimmt, treten jedoch die Grenzen dieses Ansatzes deutlich hervor. Ein einzelnes System wird schnell überlastet, weil es zu viele Informationen gleichzeitig verarbeiten muss. Genau an diesem Punkt setzt die Sub-Agent-Architektur an.
Statt auf ein monolithisches System zu setzen, wird die Arbeit gezielt auf mehrere spezialisierte Einheiten verteilt. Der Lead Agent übernimmt die Koordination, während die Sub-Agents einzelne Aufgaben bearbeiten. Das System arbeitet damit nicht mehr zentral und überladen, sondern verteilt und strukturiert.
Die Bedeutung dieses Unterschieds ist erheblich. Durch die Aufteilung in spezialisierte Einheiten entsteht ein deutlich effizienterer und stabilerer Prozess. Informationen werden gezielt verarbeitet, statt unkontrolliert angesammelt zu werden. Ergebnisse werden präziser, weil jede Einheit für einen klar definierten Bereich verantwortlich ist.
Damit schafft die Sub-Agent-Architektur die Grundlage für eine neue Art der KI-Nutzung: weg von einem überladenen Einzelsystem hin zu einem koordinierten Zusammenspiel mehrerer spezialisierter Komponenten.
Wie die Sub-Agent Architektur das Kontextproblem konkret löst
Isolierte Kontextfenster in der Sub-Agent Architektur
Das zentrale Problem klassischer KI-Systeme entsteht durch unkontrolliert wachsende Kontexte. Sub-Agent-Architekturen setzen genau an dieser Ursache an, indem sie den Kontext nicht nur verwalten, sondern gezielt begrenzen. Der entscheidende Mechanismus sind isolierte Kontextfenster.
Jeder Sub-Agent arbeitet ausschließlich mit den Informationen, die für seine konkrete Aufgabe erforderlich sind. Der Lead Agent stellt dafür einen bewusst kleinen und klar definierten Kontext bereit, anstatt den gesamten bisherigen Verlauf weiterzugeben. Auf diese Weise entsteht eine saubere Arbeitsumgebung, in der keine irrelevanten oder widersprüchlichen Informationen enthalten sind.
Die Wirkung dieses Ansatzes zeigt sich unmittelbar. Da der Sub-Agent nicht durch Altinformationen beeinflusst wird, kann er sich vollständig auf seine Aufgabe konzentrieren. Die Qualität der Ergebnisse steigt, weil die zugrunde liegende Informationsbasis klar und fokussiert bleibt. Gleichzeitig wird das ursprüngliche Problem der Kontextverschmutzung von Anfang an vermieden, da jeder Arbeitsschritt isoliert stattfindet und nicht durch vorherige Inhalte verfälscht wird.
Ergebnisübertragung als kontrollierte Verdichtung
Nachdem ein Sub-Agent seine Aufgabe abgeschlossen hat, wird das Ergebnis nicht einfach vollständig in den Hauptkontext zurückgeführt. Stattdessen erfolgt eine gezielte Verdichtung der Informationen. Der Sub-Agent liefert lediglich eine Zusammenfassung oder ein klar strukturiertes Ergebnis zurück, das auf das Wesentliche reduziert ist.
Dieser Schritt ist entscheidend, weil er den Übergang zwischen den einzelnen Arbeitsschritten kontrolliert. Anstatt den Kontext erneut anwachsen zu lassen, wird nur das übertragen, was für die Weiterverarbeitung notwendig ist. Der Lead Agent nutzt diese verdichteten Ergebnisse, um den nächsten Schritt zu planen oder weitere Sub-Agents gezielt einzusetzen.
Die Ursache vieler Kontextprobleme liegt in der ungefilterten Weitergabe von Informationen. Die Sub-Agent-Architektur ersetzt dieses Prinzip durch eine bewusste Reduktion. Die Wirkung ist ein stabiler und sauberer Hauptkontext, der nicht durch unnötige Details belastet wird. Dadurch bleibt das System auch über mehrere Verarbeitungsschritte hinweg konsistent und nachvollziehbar.
Temporäre Existenz als Schutzmechanismus
Ein weiterer zentraler Bestandteil dieses Ansatzes ist die temporäre Natur der Sub-Agents. Sie existieren ausschließlich für die Dauer einer spezifischen Aufgabe und werden anschließend vollständig entfernt. Es gibt kein dauerhaftes „Gedächtnis“ auf Ebene der einzelnen Sub-Agents.
Dieser Mechanismus adressiert ein weiteres grundlegendes Problem klassischer Systeme: die kontinuierliche Anhäufung von Daten über Zeit. In traditionellen Ansätzen bleibt jede Information im System erhalten, wodurch sich langfristig ein immer größerer Datenbestand aufbaut. Sub-Agenten hingegen hinterlassen keine Spuren außerhalb ihres Ergebnisses.
Die Bedeutung dieses Prinzips liegt in der Kontrolle über die Systemkomplexität. Da jede Einheit nach ihrer Nutzung verschwindet, kann sich kein unkontrollierter Datenbestand entwickeln. Das System bleibt dadurch schlank, effizient und berechenbar – unabhängig davon, wie viele Aufgaben nacheinander ausgeführt werden.
Zusammenspiel der Mechanismen
Erst das Zusammenspiel dieser drei Mechanismen löst das Kontextproblem vollständig. Isolierte Kontextfenster verhindern, dass irrelevante Informationen überhaupt entstehen. Die gezielte Verdichtung der Ergebnisse sorgt dafür, dass nur relevante Inhalte weitergegeben werden. Die temporäre Existenz der Sub-Agents stellt sicher, dass keine langfristige Überladung entsteht.
Aus der ursprünglichen Ursache – dem unkontrollierten Wachstum des Kontextes – wird so ein klar strukturierter Prozess. Jeder einzelne Schritt ist begrenzt, kontrolliert und auf das Wesentliche reduziert. Die Wirkung ist ein System, das auch bei komplexen Aufgaben stabil bleibt und konsistente Ergebnisse liefert.
Damit wird deutlich, dass die Sub-Agent-Architektur nicht nur eine Optimierung bestehender Prozesse darstellt, sondern einen grundlegenden Perspektivwechsel. Statt den Kontext immer weiter zu verwalten, wird er bewusst klein gehalten – und genau darin liegt die eigentliche Lösung.
So funktioniert die Sub-Agent Architektur in der Praxis
Aufgabenzerlegung als Ausgangspunkt
Der praktische Ablauf einer Sub-Agent-Orchestrierung beginnt immer mit der Analyse der Gesamtaufgabe durch den Lead Agent. Anstatt die Aufgabe direkt zu bearbeiten, wird sie zunächst in einzelne, klar definierte Teilaufgaben zerlegt. Dieser Schritt ist entscheidend, weil er die Grundlage für alle weiteren Prozesse schafft und den gesamten Ablauf strukturiert.
Der Lead Agent identifiziert, welche Schritte notwendig sind, um das gewünschte Ergebnis zu erreichen. Dabei trennt er logisch unterschiedliche Anforderungen voneinander und bringt Ordnung in eine zunächst komplex wirkende Aufgabenstellung. Eine komplexe Aufgabe wird nicht mehr als ein zusammenhängender Prozess betrachtet, sondern als Abfolge einzelner, überschaubarer Einheiten. Jede dieser Einheiten kann unabhängig geplant und ausgeführt werden.
Die Bedeutung dieser Zerlegung liegt in der Kontrolle über den gesamten Prozess. Indem jede Teilaufgabe klar abgegrenzt ist, lässt sich die Verarbeitung gezielt steuern. Fehler oder Unklarheiten bleiben auf einzelne Schritte beschränkt und übertragen sich nicht automatisch auf das gesamte System. Dadurch entsteht eine stabile und nachvollziehbare Grundlage für alle weiteren Verarbeitungsschritte.
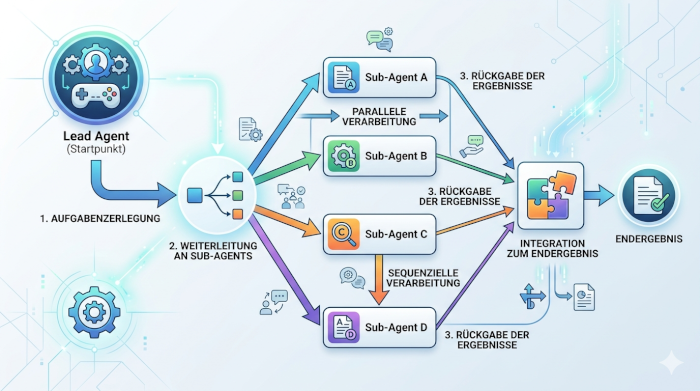
Parallele und sequenzielle Verarbeitung von Teilaufgaben
Nach der Zerlegung entscheidet der Lead Agent, in welcher Reihenfolge und Struktur die einzelnen Aufgaben bearbeitet werden. Dabei stehen zwei grundlegende Vorgehensweisen zur Verfügung: die sequenzielle und die parallele Verarbeitung.
Bei der sequenziellen Verarbeitung werden die Teilaufgaben nacheinander ausgeführt. Das bedeutet, dass das Ergebnis eines Sub-Agents als Grundlage für den nächsten Schritt dient. Diese Vorgehensweise eignet sich besonders dann, wenn die einzelnen Schritte logisch aufeinander aufbauen und voneinander abhängig sind. Jeder Schritt baut direkt auf dem vorherigen auf, wodurch eine klare und kontrollierte Entwicklung des Gesamtprozesses entsteht.
Im Gegensatz dazu ermöglicht die parallele Verarbeitung den gleichzeitigen Einsatz mehrerer Sub-Agents. Jeder Sub-Agent bearbeitet eine eigene Aufgabe unabhängig von den anderen. Da sie in isolierten Kontexten arbeiten, beeinflussen sie sich nicht gegenseitig. Dadurch wird verhindert, dass sich Informationen unkontrolliert vermischen oder gegenseitig verfälschen.
Die Wirkung dieses Ansatzes zeigt sich unmittelbar in der Effizienz des Systems. Während die parallele Verarbeitung Zeit spart und mehrere Aufgaben gleichzeitig vorantreibt, sorgt die sequenzielle Verarbeitung für Struktur und Nachvollziehbarkeit. Der Lead Agent kann flexibel entscheiden, welche Methode für die jeweilige Aufgabe geeignet ist, und passt den Ablauf entsprechend an. So entsteht ein dynamisches System, das sich an unterschiedliche Anforderungen anpassen kann.
Zusammenführung und Integration der Ergebnisse
Der letzte Schritt in der Orchestrierung ist die gezielte Zusammenführung der Ergebnisse. Nachdem die Sub-Agents ihre jeweiligen Aufgaben abgeschlossen haben, werden ihre Resultate an den Lead Agent zurückgegeben. Dieser übernimmt die Rolle der Integration und sorgt dafür, dass aus den einzelnen Ergebnissen ein konsistentes Gesamtbild entsteht.
Dabei geht es nicht nur darum, Ergebnisse einfach aneinanderzureihen. Der Lead Agent bewertet die gelieferten Informationen, setzt sie in Beziehung zueinander und kombiniert sie zu einer vollständigen Lösung. Durch die vorherige Strukturierung der Aufgaben ist klar definiert, wie die einzelnen Teile zusammengehören und in welcher Form sie integriert werden müssen.
Die Bedeutung dieses Schrittes liegt in der Sicherstellung von Konsistenz. Obwohl die Aufgaben getrennt bearbeitet wurden, entsteht am Ende ein einheitliches und stimmiges Ergebnis. Gleichzeitig bleibt der Hauptkontext kontrolliert, da nur die relevanten Resultate integriert werden und keine unnötigen Informationen übernommen werden.
Insgesamt ergibt sich daraus ein klar strukturierter Ablauf: Analyse und Zerlegung der Aufgabe, gezielte Bearbeitung durch spezialisierte Sub-Agents sowie die abschließende Integration der Ergebnisse. Dieser Prozess ersetzt den unkontrollierten Umgang mit Kontext durch einen gesteuerten und nachvollziehbaren Ablauf und bildet die Grundlage für stabile und skalierbare KI-Anwendungen.
Warum die Sub-Agent Architektur für Unternehmen entscheidend ist
Skalierbarkeit als zentrales Problem im Unternehmenskontext
Für Unternehmen liegt die größte Herausforderung beim Einsatz von KI nicht in einzelnen Anwendungsfällen, sondern in der Skalierung. Solange KI für isolierte Aufgaben genutzt wird, bleiben die Ergebnisse meist stabil und nachvollziehbar. Sobald jedoch mehrere Prozesse miteinander verknüpft werden oder komplexe Abläufe entstehen, stoßen klassische Ansätze schnell an ihre Grenzen.
Genau hier setzt die Sub-Agent-Architektur an. Sie adressiert das Skalierungsproblem, indem sie Komplexität gezielt strukturiert und aufteilt. Anstatt einen gesamten Prozess in einem einzigen System abzubilden, wird er in klar definierte Einzelschritte zerlegt und systematisch orchestriert. Dadurch werden auch umfangreiche Abläufe beherrschbar, weil jeder Teilprozess unabhängig gesteuert und kontrolliert werden kann.
Die Bedeutung für Unternehmen ist erheblich. Erst durch diese Form der Struktur wird es möglich, KI nicht nur punktuell, sondern entlang ganzer Prozessketten einzusetzen. Skalierbarkeit entsteht nicht durch immer leistungsfähigere Modelle, sondern durch eine Architektur, die Komplexität bewusst kontrolliert. Genau darin liegt die Voraussetzung für echte, unternehmensweite Automatisierung.
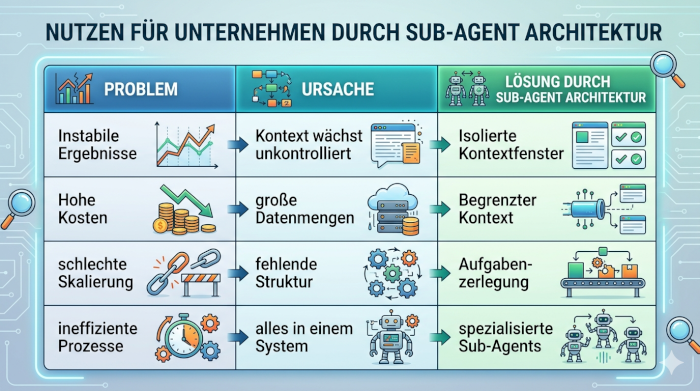
Effizienzsteigerung durch kontrollierten Ressourceneinsatz
Neben der Skalierbarkeit spielt die Wirtschaftlichkeit eine zentrale Rolle. In klassischen Systemen wächst der Kontext kontinuierlich, wodurch jede einzelne Anfrage mehr Rechenleistung erfordert. Das führt zu steigenden Kosten, ohne dass die Qualität der Ergebnisse im gleichen Maß zunimmt. Für Unternehmen bedeutet das eine ineffiziente Nutzung von Ressourcen.
Die Sub-Agent-Architektur verändert diesen Zusammenhang grundlegend. Da jeder Sub-Agent nur mit einem klar begrenzten Kontext arbeitet, bleibt der Rechenaufwand pro Aufgabe kontrollierbar. Es werden ausschließlich die Informationen verarbeitet, die tatsächlich für die jeweilige Aufgabe notwendig sind. Dadurch sinken die Kosten pro Verarbeitungsschritt, während die Qualität stabil bleibt.
Die Wirkung zeigt sich besonders bei wiederkehrenden oder mehrstufigen Prozessen. Anstatt stetig wachsende Datenmengen zu verarbeiten, bleibt das System schlank und fokussiert. Für Unternehmen entsteht daraus ein klarer Vorteil: KI wird nicht nur leistungsfähig, sondern auch wirtschaftlich einsetzbar. Effizienz entsteht in diesem Fall nicht durch mehr Leistung, sondern durch eine bessere Strukturierung der Prozesse.
Grundlage für autonome und selbststeuernde Systeme
Der vielleicht wichtigste Aspekt liegt in der langfristigen Perspektive. Sub-Agent-Architekturen schaffen die strukturelle Grundlage für Systeme, die nicht nur einzelne Aufgaben ausführen, sondern ganze Prozesse eigenständig steuern können. Der Lead Agent übernimmt dabei die Rolle einer zentralen Steuerinstanz, während Sub-Agents flexibel eingesetzt werden, um einzelne Schritte umzusetzen.
Für Unternehmen eröffnet das neue Möglichkeiten. Prozesse können nicht nur automatisiert, sondern auch dynamisch angepasst werden. Entscheidungen werden innerhalb des Systems getroffen, basierend auf klar definierten Strukturen und den jeweiligen Ergebnissen. Damit entsteht eine neue Form der Automatisierung, die über einfache Regelwerke hinausgeht.
Die Bedeutung reicht dabei über reine Effizienzgewinne hinaus. Sobald Systeme in der Lage sind, komplexe Abläufe eigenständig zu koordinieren, verändern sich auch bestehende Geschäftsmodelle. Aufgaben, die bislang manuelle Abstimmungen erfordert haben, können vollständig durch KI gesteuert werden. Unternehmen gewinnen dadurch nicht nur Geschwindigkeit, sondern auch neue Spielräume in der Organisation und Optimierung ihrer Prozesse.
Insgesamt wird deutlich, dass die Sub-Agent-Architektur nicht nur eine technische Weiterentwicklung darstellt, sondern eine strategische Grundlage für den Einsatz von KI im Unternehmen bildet. Sie verbindet Skalierbarkeit, Effizienz und Automatisierung zu einem Ansatz, der den praktischen Einsatz von KI erstmals auf ein stabiles und kontrollierbares Fundament stellt.
Grenzen und Herausforderungen der Sub-Agent Architektur
Komplexität der Implementierung
So klar die Vorteile der Sub-Agent-Architektur in der Theorie erscheinen, so anspruchsvoll ist ihre Umsetzung in der Praxis. Im Unterschied zu klassischen KI-Anwendungen, bei denen ein einzelnes System eingesetzt wird, müssen hier mehrere Agenten koordiniert und aufeinander abgestimmt werden. Der Lead Agent übernimmt dabei eine zentrale Rolle: Er muss Aufgaben korrekt zerlegen, geeignete Sub-Agents auswählen und den gesamten Ablauf kontinuierlich überwachen.
Diese zusätzliche Steuerungsebene erhöht die Komplexität deutlich. Fehler können nicht nur während der Ausführung entstehen, sondern bereits in der Planungsphase. Werden Aufgaben falsch aufgeteilt oder unlogisch priorisiert, wirkt sich das unmittelbar auf die Qualität der Ergebnisse aus. Für Unternehmen bedeutet das eine spürbar höhere Einstiegshürde. Der Aufbau eines solchen Systems erfordert ein klares Verständnis der eigenen Prozesse sowie eine präzise Strukturierung der Aufgaben.
Die Konsequenz ist eindeutig: Eine Sub-Agent-Architektur lässt sich nicht einfach aktivieren. Sie muss gezielt konzipiert und sauber umgesetzt werden. Ohne diese Grundlage entsteht kein stabiler Vorteil, sondern im ungünstigsten Fall ein System, das zwar komplexer ist, aber keinen zusätzlichen Nutzen liefert.
Abhängigkeit von klaren Aufgabenstrukturen
Ein weiterer kritischer Punkt liegt in der starken Abhängigkeit von der Qualität der Aufgabenzerlegung. Die gesamte Architektur basiert darauf, dass komplexe Prozesse sinnvoll in Teilaufgaben unterteilt werden. Diese Aufteilung entscheidet maßgeblich darüber, ob das System effizient arbeitet oder nicht.
Sind Aufgaben zu grob definiert, entsteht innerhalb einzelner Sub-Agents erneut ein zu großer Kontext. Das ursprüngliche Problem wird dadurch nicht gelöst, sondern lediglich verlagert. Werden Aufgaben hingegen zu kleinteilig oder unlogisch geschnitten, steigt der Koordinationsaufwand unnötig an. In beiden Fällen leidet sowohl die Effizienz als auch die Qualität der Ergebnisse.
Die Ursache liegt daher weniger im System selbst als in der Art seiner Anwendung. Die Sub-Agent-Architektur stellt ein strukturelles Werkzeug bereit, dessen Nutzen stark davon abhängt, wie präzise Prozesse modelliert werden. Für Unternehmen bedeutet das, dass sie ihre Abläufe genau verstehen und klar definieren müssen, bevor diese Architektur sinnvoll eingesetzt werden kann.
Grundprobleme der KI bleiben bestehen
Trotz ihrer strukturellen Vorteile beseitigt die Sub-Agent-Architektur nicht die grundlegenden Schwächen von KI-Systemen. Probleme wie Halluzinationen, Fehlinterpretationen oder inkonsistente Entscheidungen können weiterhin auftreten. Auch wenn die Architektur dazu beiträgt, die Auswirkungen dieser Probleme zu reduzieren, werden sie nicht vollständig eliminiert.
Der entscheidende Unterschied liegt in der besseren Kontrollierbarkeit. Durch die Aufteilung in einzelne Schritte lassen sich Fehler gezielter eingrenzen und nachvollziehen. Ein fehlerhaftes Ergebnis bleibt auf einen Teilprozess beschränkt, anstatt sich unkontrolliert durch den gesamten Workflow fortzusetzen. Dennoch bleibt die inhaltliche Qualität der Ergebnisse weiterhin von den Fähigkeiten der eingesetzten Modelle abhängig.
Für Unternehmen ist diese Einordnung entscheidend. Die Sub-Agent-Architektur stellt keine perfekte Lösung dar, sondern einen Ansatz, um bestehende Probleme strukturierter zu managen. Sie verbessert die Organisation, Effizienz und Skalierbarkeit von KI-Systemen, ersetzt jedoch nicht die Notwendigkeit, Ergebnisse kritisch zu prüfen und Prozesse aktiv zu überwachen.
Fazit
Das zentrale Hindernis moderner KI-Anwendungen liegt weniger in der reinen Leistungsfähigkeit der Modelle als im Umgang mit Kontext. Sobald Aufgaben komplexer werden und mehrere Verarbeitungsschritte umfassen, führt der unkontrollierte Aufbau von Informationen zu Instabilität, ungenauen Ergebnissen und einem ineffizienten Einsatz von Ressourcen. Genau an diesem Punkt wird die Grenze klassischer KI-Nutzung sichtbar.
Die Sub-Agent-Architektur setzt genau hier an und adressiert das Problem auf struktureller Ebene. Anstatt immer größere Kontexte zu verwalten, wird der gesamte Arbeitsprozess bewusst aufgeteilt. Ein Lead Agent übernimmt die Steuerung, während spezialisierte Sub-Agents klar abgegrenzte Aufgaben in isolierten Kontexten bearbeiten. Diese Trennung sorgt dafür, dass das System kontrollierbar bleibt, Ergebnisse konsistenter werden und auch komplexe Prozesse erstmals zuverlässig umgesetzt werden können.
Für Unternehmen stellt das einen entscheidenden Fortschritt dar. KI kann dadurch nicht mehr nur punktuell eingesetzt werden, sondern entlang kompletter Prozessketten. Skalierbarkeit entsteht dabei nicht durch zusätzliche Rechenleistung, sondern durch eine bessere Organisation der Abläufe. Gleichzeitig verbessert sich die Wirtschaftlichkeit, weil unnötiger Kontext vermieden und Ressourcen gezielter eingesetzt werden.
Trotz dieser Vorteile ist die Sub-Agent-Architektur kein Allheilmittel. Die Qualität der Ergebnisse bleibt weiterhin abhängig von der Struktur der Aufgaben und den Fähigkeiten der eingesetzten Modelle. Fehleranfälligkeit und Unsicherheiten verschwinden nicht, werden jedoch deutlich besser kontrollierbar.
In der Gesamtbetrachtung markiert dieser Ansatz einen wichtigen Entwicklungsschritt. Er schafft die Grundlage für produktive und skalierbare KI-Systeme und eröffnet neue Möglichkeiten für Automatisierung und Prozesssteuerung, ohne die grundlegenden Herausforderungen der Technologie auszublenden.
FAQ
1. Was ist eine Sub-Agent Architektur bei KI?
Eine Sub-Agent Architektur beschreibt ein System, in dem ein Lead Agent Aufgaben auf spezialisierte Sub-Agents verteilt, um komplexe Prozesse strukturiert zu lösen.
2. Warum haben KI-Systeme Probleme mit Kontext?
Weil sich im Kontextfenster irrelevante Informationen ansammeln. Das führt zu unklaren Entscheidungen und schlechteren Ergebnissen.
3. Wie lösen Sub-Agents das Kontextproblem?
Durch isolierte Kontextfenster, klare Aufgabenverteilung und verdichtete Ergebnisübergabe wird Kontextverschmutzung verhindert.
4. Wann sollte man Sub-Agenten einsetzen?
Vor allem bei komplexen, mehrstufigen Aufgaben und automatisierten Prozessen im Unternehmen.
5. Sind Sub-Agent-Systeme besser als klassische KI?
Bei komplexen Workflows ja, da sie strukturierter arbeiten und stabilere Ergebnisse liefern.
6. Was ist der Unterschied zwischen Lead Agent und Sub-Agent?
Der Lead Agent steuert den Prozess, Sub-Agents führen spezialisierte Aufgaben aus.7. Ist die Sub-Agent Architektur skalierbar?
Ja, gerade durch die Aufteilung in einzelne Aufgaben wird Skalierung erst möglich.




